1️⃣ 자료구조(Data Structure)란?
- 데이터를 효율적으로 저장하고 관리하는 방식
- 시간과 공간을 최적화하여 문제 해결을 돕는다
2️⃣ 자료구조 + 알고리즘 = 프로그램
- 자료구조: 데이터를 효과적으로 저장하고 검색하는 방법
- 알고리즘: 주어진 문제를 해결하기 위한 절차나 방법
3️⃣ "효율적"이라는 것은?
- 빠른 시간(시간 복잡도)
- 적은 공간(공간 복잡도)

📌 자료 구조의 형태별 분류
1️⃣ 단순 구조 (Simple Structure)
- 가장 기본적인 데이터 형태
- 예시: 정수, 실수, 문자, 문자열
2️⃣ 선형 구조 (Linear Structure)
- 데이터가 순차적으로 나열된 형태
- 한 개의 데이터 다음에 한 개의 데이터만 연결됨
- 예시: 배열(Array), 연결 리스트(Linked List), 스택(Stack), 큐(Queue)
3️⃣ 비선형 구조 (Non-Linear Structure)
- 데이터가 계층적 혹은 네트워크 형태로 연결됨
- 하나의 데이터가 여러 개의 데이터와 연결될 수 있음
- 예시: 트리(Tree), 그래프(Graph)
4️⃣ 파일 구조 (File Structure)
- 데이터를 디스크, SSD, 클라우드 등 저장 장치에 저장하는 방식
- 예시: 순차 파일(Sequential File), 직접 파일(Direct File), 색인 파일(Indexed File)
📌 자료 추상화(Data Abstraction)란?
자료 추상화는 데이터의 구체적인 구현을 숨기고, 중요한 기능만을 제공하는 개념입니다.
1️⃣ 데이터의 세부 사항을 감추고, 사용자가 쉽게 사용할 수 있도록 함
2️⃣ 데이터를 여러 수준(Level)으로 관리
3️⃣ 추상화 계층을 통해 복잡성을 줄이고, 재사용성을 높임
📌 추상 자료형(ADT, Abstract Data Type)
- 데이터와 연산을 묶은 추상적인 개념
- 구현 방식은 감추고, 인터페이스만 제공
- 예시: 스택(Stack), 큐(Queue), 리스트(List)
📌 추상화 vs. 구체화
- 추상화(Abstraction): 핵심 개념만 남기고 불필요한 세부 사항을 제거
- 구체화(Implementation): 추상화된 개념을 실제 코드로 구현하는 과정
🔹 자료와 연산에서의 추상화와 구체화 관계
- 자료 추상화 → 데이터를 논리적으로 표현 (예: 리스트, 트리)
- 연산 추상화 → 데이터에 적용할 연산만 정의 (예: 삽입, 삭제)
- 구체화는 이를 실제로 구현하는 단계 (예: 배열, 연결 리스트로 구현)
📌 알고리즘 표현 4가지 방법
1️⃣ 자연어(Natural Language)
- 사람이 이해할 수 있도록 일반 문장으로 서술
- 예) "배열을 순회하며 가장 큰 값을 찾는다."
2️⃣ 순서도(Flowchart)
- 알고리즘을 도형과 화살표로 시각적으로 표현
- 예) 결정 노드(다이아몬드), 프로세스(사각형) 등 활용
3️⃣ 의사코드(Pseudocode)
- 프로그래밍 언어처럼 보이지만, 문법이 없는 비형식적인 코드
- 예)
복사편집최대값 = 첫 번째 원소 배열의 모든 원소를 확인하며 현재 원소가 최대값보다 크면 최대값을 갱신
4️⃣ 프로그래밍 코드(Programming Code)
- 실제 프로그래밍 언어로 작성된 코드

📌 알고리즘(Algorithm)이란?
- 문제를 해결하기 위한 절차나 방법
- 유한한 단계에서 연산을 수행하여 결과를 도출
📌 알고리즘의 5가지 조건
1️⃣ 입력(Input)
- 제로 이상의 입력이 있어야 함
2️⃣ 출력(Output)
- 최소 하나 이상의 결과(출력)가 나와야 함
3️⃣ 명확성(Definiteness)
- 각 단계가 명확하고 애매하지 않게 정의되어야 함
4️⃣ 유한성(Finiteness)
- 유한한 시간 안에 종료해야 함 (무한 루프 X)
5️⃣ 효율성(Efficiency)
- 불필요한 연산 없이 최적의 방법으로 수행되어야 함
📌 Specification(명세)란?
- 시스템이나 프로그램의 동작, 기능, 요구사항을 기술하는 문서 또는 과정
- 소프트웨어 개발에서 설계, 개발, 테스트 기준을 제공
🔹 가상코드란?
- 가상코드, 즉 알고리즘 기술언어(ADL)를 사용하여 프로그래밍 언어의 일반적인 형태와 유사하게 알고리즘을 표현
- 특정 프로그래밍 언어가 아니므로 직접 실행 불가
📌 알고리즘 성능 분석 기준
알고리즘의 성능을 평가하는 주요 기준은 정확성, 효율성, 최적성, 확장성, 단순성 등이 있습니다.
🔹 1. 정확성 (Correctness)
- 알고리즘이 문제를 정확하게 해결하는지 여부
- 모든 입력에 대해 예상된 출력이 나오는지 확인
- 예시:
- 정렬 알고리즘이 항상 오름차순으로 정렬되는지 검증
🔹 2. 시간 복잡도 (Time Complexity)
- 알고리즘이 수행되는 데 걸리는 시간
- 보통 입력 크기(n) 에 대한 Big-O 표기법으로 표현
- 예시:
- 선형 탐색(Linear Search): O(n)
- 이진 탐색(Binary Search): O(log n)
🔹 3. 공간 복잡도 (Space Complexity)
- 알고리즘이 추가적으로 사용하는 메모리 양
- 입력 크기(n)에 따라 증가하는 공간의 크기 분석
- 예시:
- 배열을 사용한 정렬: O(n)
- 퀵 정렬(Quick Sort, in-place): O(log n)
🔹 4. 최적성 (Optimality)
- 해당 문제를 해결하는 가장 효율적인 알고리즘인지 평가
- 불필요한 연산이 없는지 확인
- 예시:
- 병합 정렬(O(n log n)) vs. 버블 정렬(O(n²))
🔹 5. 확장성 (Scalability)
- 입력 크기가 커질 때도 효율적으로 동작하는지 평가
- 성능이 급격히 저하되지 않는 알고리즘이 필요
- 예시:
- O(n log n) 알고리즘은 O(n²)보다 큰 데이터에서 성능이 우수
🔹 6. 단순성 (Simplicity)
- 알고리즘이 이해하기 쉽고 구현하기 쉬운지 평가
- 코드가 지나치게 복잡하지 않고 가독성이 좋은지 고려
- 예시:
- 버블 정렬은 단순하지만, 퀵 정렬이 더 효율적
✅ 공간 복잡도(Space Complexity)
- 알고리즘이 사용하는 메모리 크기
- 추가적인 저장 공간이 얼마나 필요한가?
- 예시:
- 배열 정렬: O(n) (추가 공간 필요)
- 퀵 정렬(in-place): O(log n) (추가 공간 거의 없음)
✅ 시간 복잡도(Time Complexity)
- 알고리즘이 실행되는 데 걸리는 시간
- 입력 크기(n)에 따라 연산 횟수가 얼마나 증가하는가?
- 예시:
- 선형 탐색: O(n) (입력 크기만큼 반복)
- 이진 탐색: O(log n) (빠르게 검색)
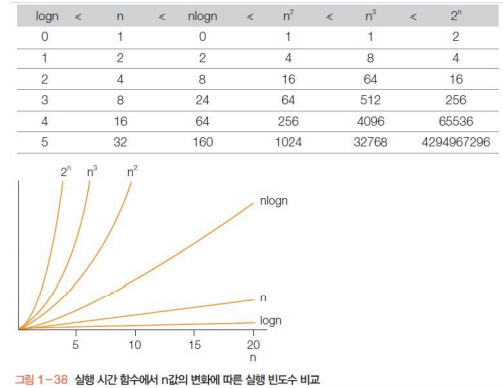
📌 빅-오 표기법(Big-O Notation)란?
- 알고리즘의 성능(시간 복잡도 & 공간 복잡도)을 최악의 경우 기준으로 표현하는 방법
- 입력 크기(n)에 따라 실행 시간이 증가하는 패턴을 나타냄
- 연산 횟수의 증가율을 수학적으로 표현
- 함수의 상한을 나타내기 위한 표기법
📌 주요 빅-오 표기법과 예시
빅-오 표기법 이름 설명 예시 (알고리즘)
| O(1) | 상수 시간(Constant) | 입력 크기에 관계없이 항상 같은 시간 소요 | 배열 인덱싱 arr[i] |
| O(log n) | 로그 시간(Logarithmic) | 입력이 커져도 실행 시간이 급격히 증가하지 않음 | 이진 탐색(Binary Search) |
| O(n) | 선형 시간(Linear) | 입력 크기에 비례하여 실행 시간 증가 | 선형 탐색(Linear Search) |
| O(n log n) | 로그-선형 시간 | 빠른 정렬 알고리즘(병합 정렬, 퀵 정렬) | 퀵 정렬(Quick Sort) |
| O(n²) | 이차 시간(Quadratic) | 중첩된 반복문으로 인해 실행 시간 급증 | 버블 정렬(Bubble Sort) |
| O(2ⁿ) | 지수 시간(Exponential) | 입력 크기가 증가하면 실행 시간 급격히 증가 | 피보나치 재귀(Fibonacci) |
| O(n!) | 팩토리얼 시간(Factorial) | 가장 비효율적인 알고리즘 | 외판원 문제(Brute Force) |
(알아두면 좋음. 수업에선 넘어감)
✅ Big-Omega (Ω) → 최상의 경우 (Best Case)
알고리즘이 가장 빨리 끝날 때의 실행 시간 예시: 이미 정렬된 데이터에서 버블 정렬의 경우 O(n) (한 번만 확인하면 끝)
✅ Theta (Θ) → 평균적인 경우 (Average Case)
Big-O와 Big-Omega가 같을 때, 알고리즘이 항상 일정한 성능을 보일 때 사용 예시: 퀵 정렬(Quick Sort)은 최악 O(n²), 최선 O(n log n)이지만 평균적으로 Θ(n log n)
'2025-소프트웨어과 2학년 > 자료구조(C 이용)' 카테고리의 다른 글
| 자료구조(C언어 활용)-01(1) (0) | 2025.03.14 |
|---|